I had an interesting time over the new year period.
For some time now I have run a tor node on a VPS at ThrustVPS. I also run my tails mirror on a VPS at the same provider. Their network has always struck me as pretty poor (response times to ssh login is particularly bad, and the servers sometimes go off-line for no apparent reason) but over the last month I had worse than average performance, and frankly appalling service response.
I initially chose thrust (then known as damnvps for some odd reason) because they offered “1TB of transfer” per month on all their VPSs. Tor is a particularly voracious bandwidth hog and needs to be throttled to keep it in check. Fortunately the configuration file allows this fairly easily and I had mine set to limit my traffic to no more than 30 GiB per day – i.e. less than the supposed monthly limit. My tails mirror is similarly throttled, though I do that in lighttpd and it is a bit more tricky and less accurate
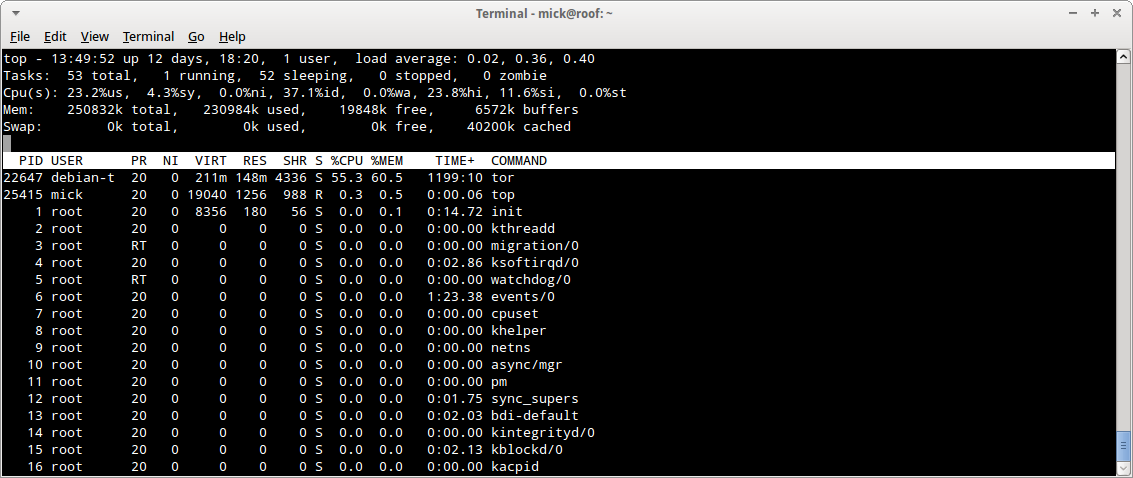
Until recently I have monitored all my servers through munin. But a while back I moved the VPS which acted as the munin master from one place to another and did not get around to reconfiguring munin on that node. Big mistake. It meant that I had no records of the activity on my tails mirror and tor node over a critical period when thrust seemed to be even more unreliable than usual. Munin monitor notwthstanding, I still check my servers pretty regularly and I found that the thrust VPSs seemed to be going off-line too frequently. One server, the tor node, went down on the 19th, 22nd, and 29th of december and the tails mirror also went down on the 22nd. They came back up when rebooted through the web administration interface, but performance was pretty dire. So I complained to support.
My first email to support on the 29th of december elicited an interesting response. They replied:
“We have stopped your server 109.169.77.131 since it is causing DDOS attack to the hostnode 15xnuk. It is related to the performance issue of the host node we have no other choice without stopping you.Please do take proper measures, install the proper anti virus on the server make through scan on your server and update us.”
DDOS eh? So I asked for more detail and got the following in response:
“I have been started your server when you opened the ticket. And we are sorry for you to stop the VPS without any information. We are monitoring this node for the past few hours and if your IP DDOS again we may forced to stop it again. Please do take measures and monitor your VPS.”
In my email to support I had explained that the VPS in question ran a tor node (though they should have known that because I specifically told them that when I paid for it) and that heavy traffic from multiple IP addresses inbound to my tor port was perfectly normal. Moreover, I could not believe that my tor mode would be the only one targeted by a DDOS if someone didn’t like tor (and lots of people don’t) so I checked with colleagues on the tor-relays mailing list. No-one else seemed to be having problems. Nevertheless, I shut tor down while I investigated and fired off another email to support asking them again to answer my earlier questions. In particular I said:
“Specifically,
– is the “DDOS” aimed at my IP address, and my IP address alone (and only to port 443)?
– is all the traffic coming to my IP address from tor nodes, and only tor nodes (this is easy to check, the addresses are public)?
If the traffic has now dropped, and the answer to either question is yes, then this is not a DDOS, it is expected behaviour of
a tor node.
I am about to turn tor back on. Watch the traffic build again.”
I received another unhelpful reply:
“I could see that most traffic coming from https. So please monitor the https ports. The host node is stable now so I think the issue get compromised.
Please back to us if you need any further assistance.
Thanks for the understanding.”
Note that at this stage there has been no answer to my questions, nor has there been any explanation of why my tails mirror went down, or the tor node went down on the days before the 29th. But by now I suspected simply that the thrust network was so heavily oversold that whenever my servers came close to using anywhere near their alloted bandwidth, they were arbitrarily shut down. This was confirmed for me by another email from support which said:
“Please note that there exists a script in the node to reboot the servers having high load (thereby causing load spike in the node) inorder to get the load in the node to be stable. And we are considered the high resource using is also as a DDOS attack.”
I interpreted this to mean that any high traffic is seen by thurst as a DDOS and they simply shut down the target IP. Way to go thrust. If there /is/ a DDOS attack on a node then you have just done the attacker’s job for them. Worse, they don’t bother to tell the customer.
By now (the 31st of December) my server was back on-line, but it went down again later that day. So I complained again and got another stupid reply:
“Your server was suspended due to high ddos attack on the host node and it affected our host node performance heavily.
Also it is related to the performance issue of the host node we can’t unsuspend your server for the next 24 hours , please update us after the 24 hours complete then only I can unsuspend your server.”
Which I took to mean that they would not turn my server back on again for another 24 hours.
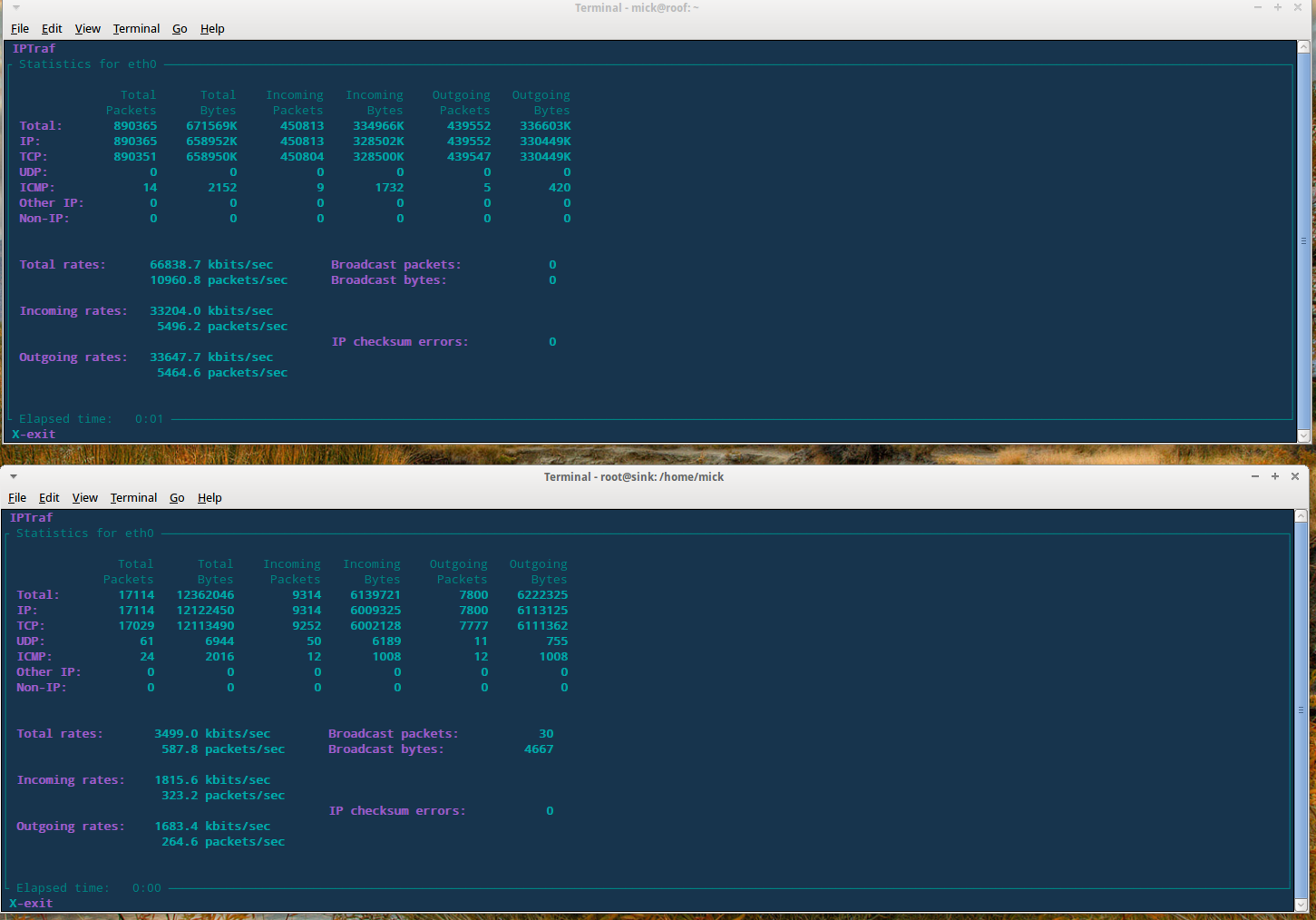
Along with the stupid reply, I was given a snippet of log traffic to/from my server. Guess what, it showed traffic from high numbered ports on a range of IP addresses to/from my port 443 (I run tor on 443 – thrust support seemed to think that this meant it must be https). To anyone who knows anything about IP networking this is indicative of client systems communicating with a server. In my case, it is tor clients trying to connect through my tor node on their way somewhere else. Thrust don’t get this, or don’t want to. All they see is lots of traffic so they shut it down.
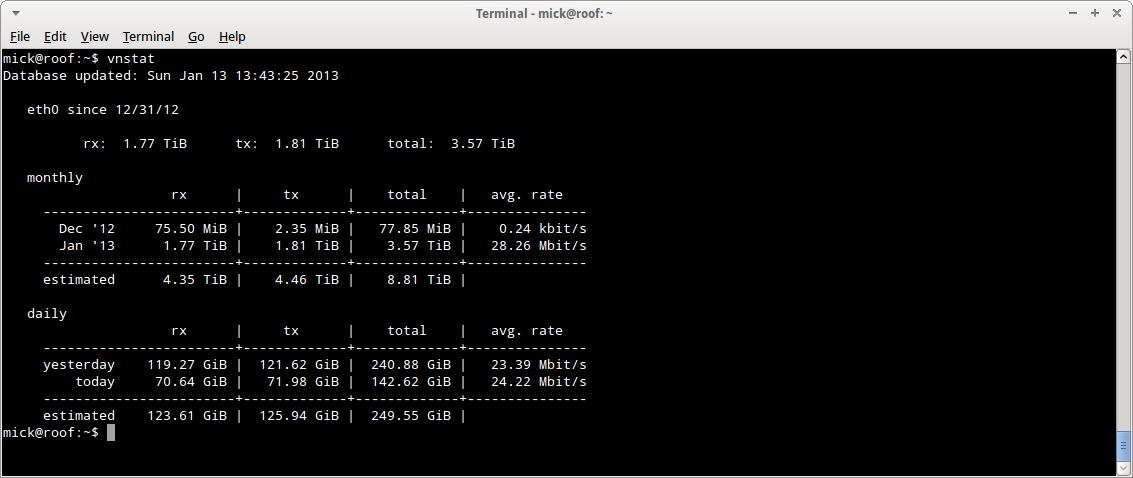
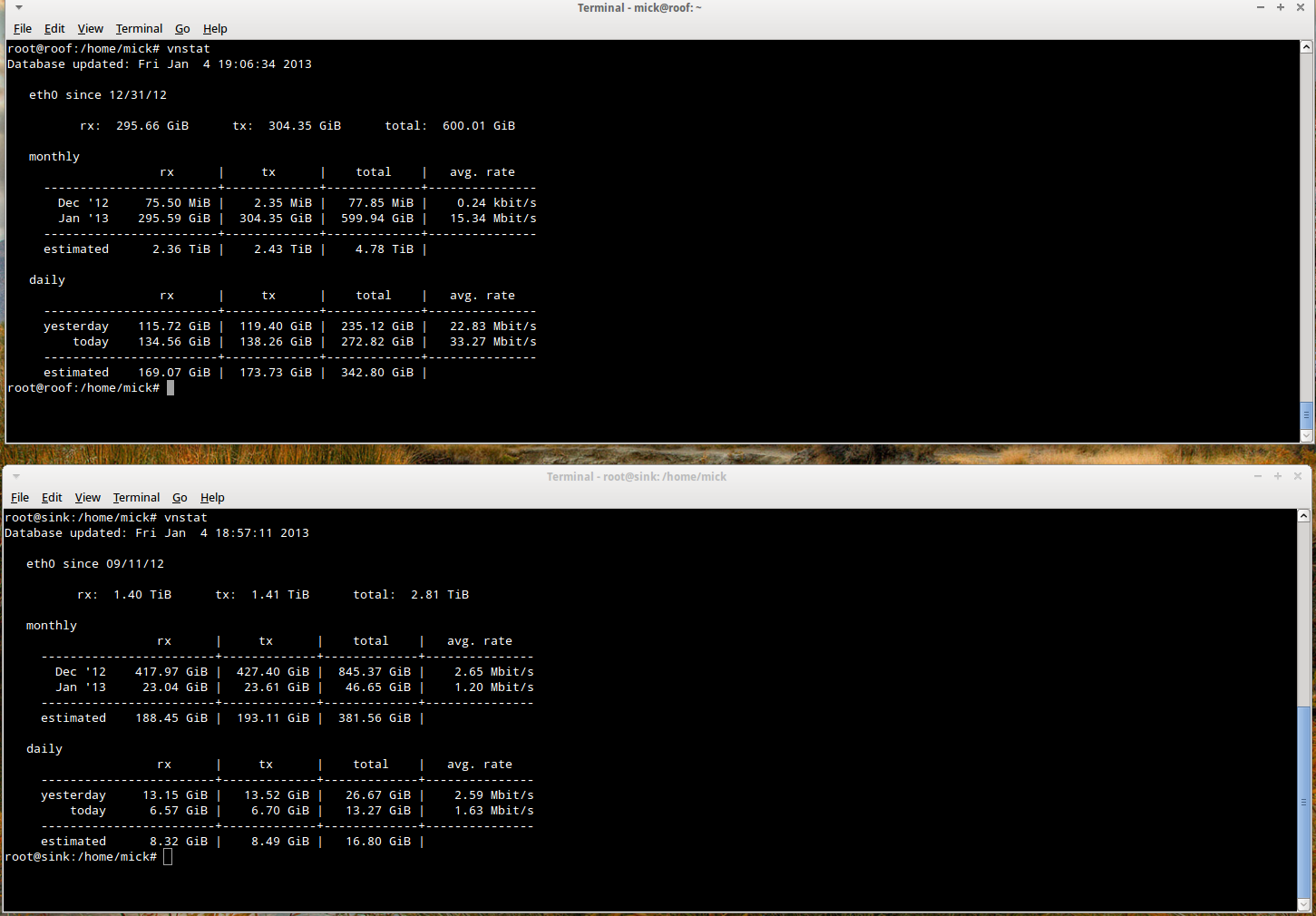
Now note carefully here that at no time have they proved DDOS. My vnstat traffic stats on the VPS show that I am well within my bandwidth allowance for the month and the daily traffic is not unusually high either. The only possible problem is that I am attempting to use the bandwidth they advertise as available, and that I have paid for. I confess I was a little abrupt in my reply to this nonsense and I asked that the issue be escalated to management.
Things then went quiet. I think I pissed off the support team.
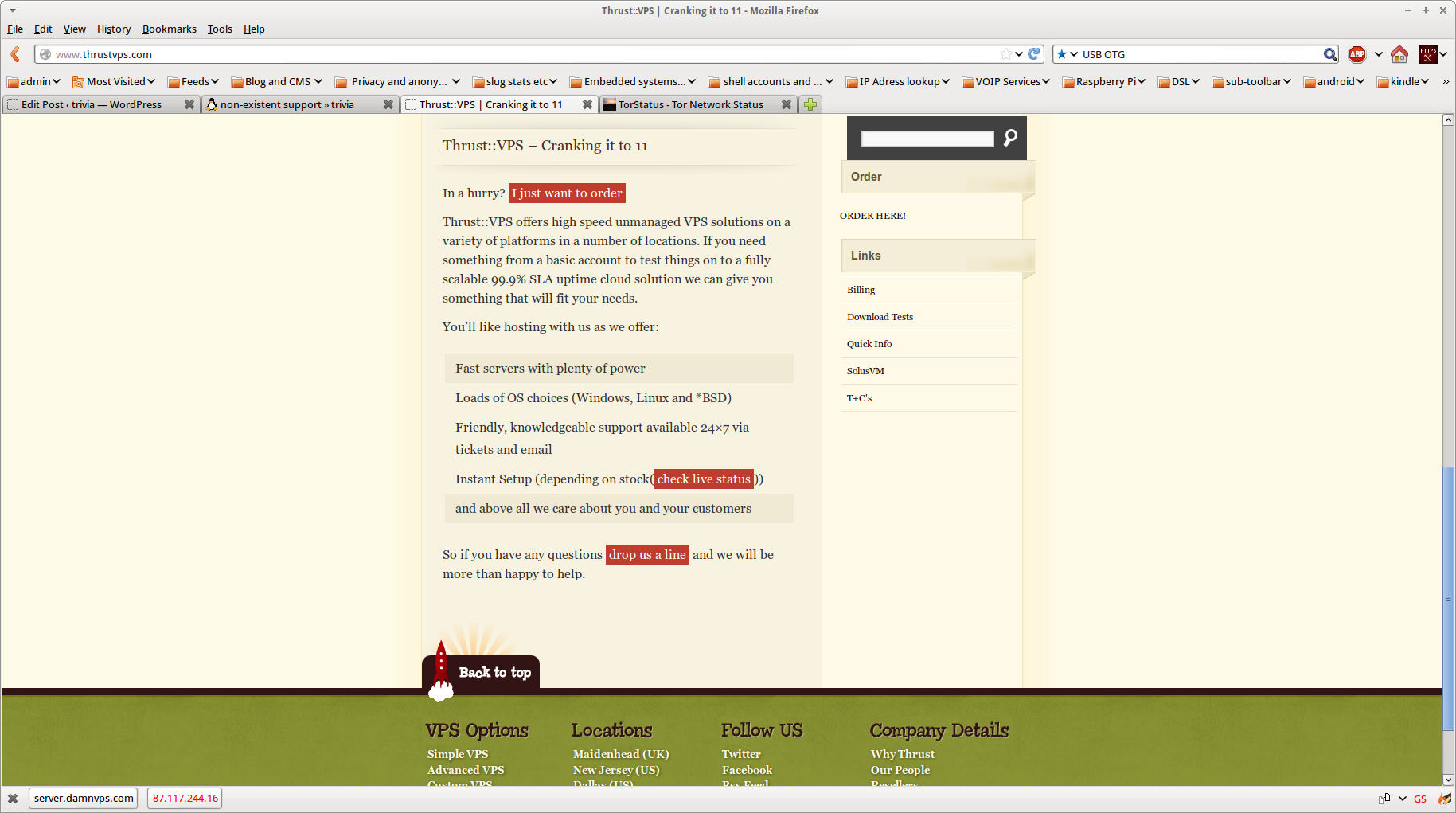
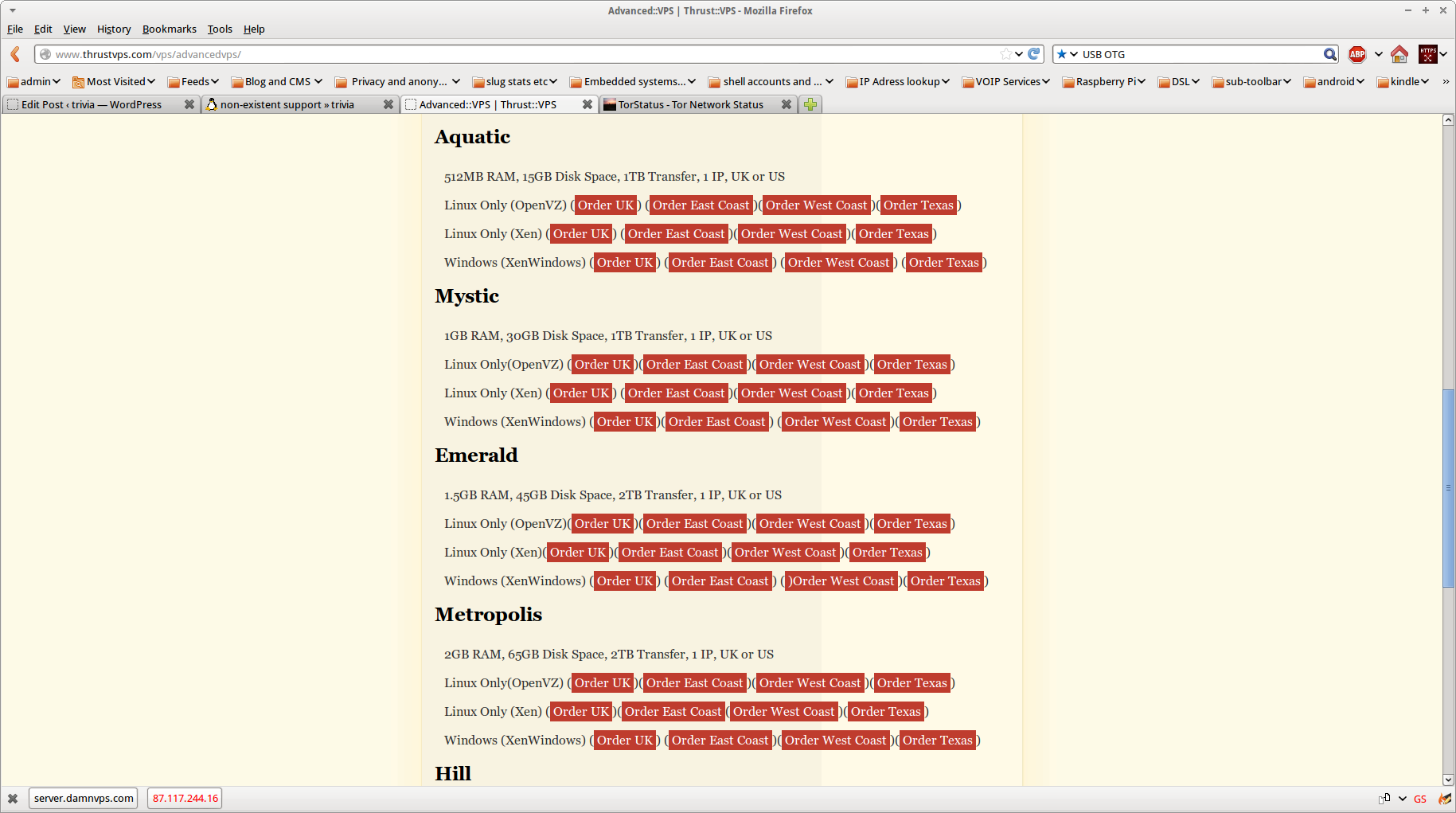
As an aside it is worth taking a look at the thrustVPS sales page:
I particularly like the “Friendly, knowledgeable support available 24×7” and “above all we care about you and your customers“.
and the page advertising the service I actually paid for:
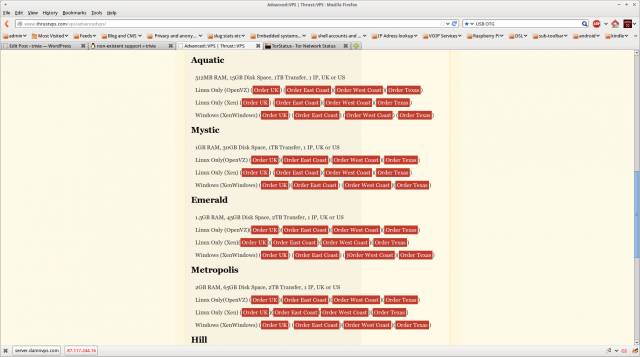
Note carefully the claimed “512MB RAM, 15GB Disk Space, 1TB Transfer, 1 IP, UK or US” because this is where it gets interesting. On the 2nd of January I received an email from one Gareth Akehurst saying
“Hello Mick,
Escalations was unavailable during the holiday period, how can I help?
Regards,
Gareth Akehurst”
(so clearly “escalations” don’t work 24/7)
In answer to my response querying why my server had been shut down, Gareth replied:
“This is standard procedure for our clients, all nodes are on a 100mBits network, the node you are currently on shares that connection with 59 other virtual servers, if you are requiring a high traffic service it may be worth considering a low contention vps which the nodes are limited to no more than 25 vpses.”
Note that “all nodes are on a 100mBits network”. So at best, my VPS is on a machine which has 60 VPS instances trying to share a 100Mbit/s network, and at worst, the whole damned network of hardware is on a 100 Mbit backbone. I’ve got one of those at home for pitys sake. Now, since my vnstat daily stats on that VPS show I was running at 3.1 Mbit/s for a daily throughput of around 30 GiB, there is no way on earth that all 60 customers could /ever/ get their full monthly allowance. In fact, if all of us tried, we would be running at nearly twice the total available bandwidth of the backbone. No wonder the network response was crap. And no wonder thrust arbitrarily shut down customers with “high” loads. The network is so hugely oversold it is criminal.
The ISP industry has a pretty shoddy reputation for advertising (see 8 Mbit/s broadband advertising for example) but this is frankly taking the piss. If I buy a product that says I should get 1TB of transfer, I expect to get that. If they can’t provide that (and on their maths, they can’t) then I have been missold. Worse, I have been treated like an idiot and lied to about DDOS attacks. If I hadn’t paid in advance for the two servers I have with thrust, I’d close the account now. But oddly, they do not refund unhappy customers. So I’ll sit and use as much as possible under my current contract and then leave.
Meanwhile, if anyone else is considering thrustvps – just don’t. Look elsewhere. There are much better providers out there. Bytemark is by far the best. Unfortunately they don’t offer a high bandwidth allowance at a price point I am prepared to pay for a service which I give away.
(In the interests of transparency and honesty, I have posted here the entire email exchange between myself and thrust “support”. Read it and weep.)
Happy New Year.